NBA Game Predictor
Using Machine Learning and Momentum to Predict More Accurate Game Results
I grew up in love with someone named “basketball”. As a child, anything that could satiate my hooping fixation snuck its way into my life. I remember being eight years old on weekday nights—no access to cable, and no way to watch games—half focusing on my times tables homework while i watched the box score and shot charts update on NBA.com for my Celtics. Back then, I had to cheer and raise my fists for little green dots on my computer clutching it out for a single digit win. As lackluster as those viewing experiences were, it taught me to study the game through the numbers. I couldn’t see the players physically play. So I needed to be Sherlock Holmes for a bit, deducing any information I could get from their statistics. And here lies my inspiration for developing this model.

The Idea
Since the early 2000s when I began watching the NBA, the sport saw an explosion of statistics and data science that every team, fan, and everyone in between sought to take advantage of. Sabermetrics became a big buzz word that got teams thinking about the how little the power of statistics they really wielded. Stephen Curry taught the world that 3 is greater than 2, and had teams realizing how far behind they were when it comes to leveraging the data at their disposal. The advancement of computer vision techniques and the AI boom have done nothing to slow down that trend.
While today, many models attempt to deliver accurate game predictions, one trend to be found amongst them is a bias toward utilizing baseline metrics when making predictions. A model may use season averages to predict the outcome of a single game. Another model may take it one step further and factor in the strength of an opponent in that calculation. But maybe a team’s star player is coming back from an injury. Maybe their team has been shooting lights out for the last few games. The reality is that momentum is an extremely important factor when it comes to predicting the quality of a team, and the outcome of their games.
Take the 2024-25 Indiana Pacers. They came into the playoffs seeded 4th in their conference. They were +2200 underdogs to make it to the NBA Finals. Yet they blew by every opponent they faced in their conference, most being favorites to win. So what happened? Did they just get lucky? Or did analysts and bettors underestimate the team’s strength? As it turns out, the Pacers played spotty early in the season, but after midway through the season, they held the second best record in the league and had not lost back to back games. And going into the playoffs, the monsters playing at the end of the season, were not the +2200 players many fans had thought them to be.
This is where my idea to factor in momentum comes into play.
The Model
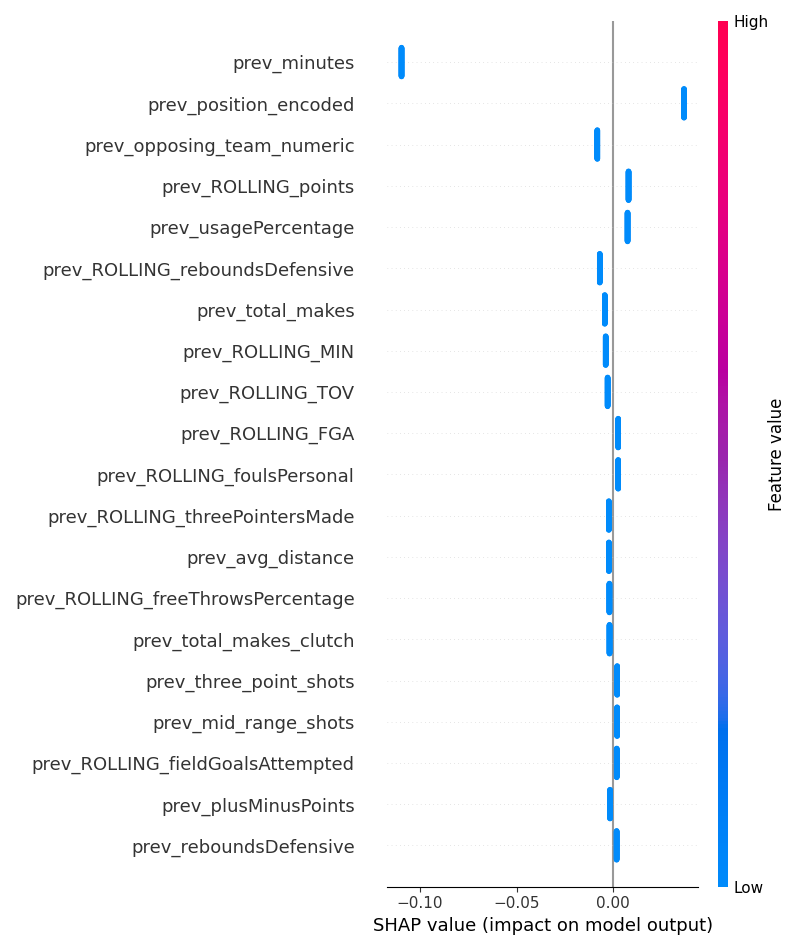
The main objective behind this experiment is to observe how accurate a model’s predictions could be when including momentum based data alongside traditional statistics. To collect this data, I took advantage of nba_api, which provides up to date data on past and current NBA games. With a simple api call, I could collect all the data I needed.
The training set consists of two types of data. The first type is static data. This includes traditional and advanced statistics from Points Scored to True Shooting Percentage. The second type is rolling data. This was calculated using a mean of an individual player’s last five games, producing rolling data that could be applied to any game prediction.
From testing multiple model architectures, I found that an XGBoost Multi Classifier produced the best results, operating with an 80% R² value, and with predictions being produced relatively quickly compared to other architectures.
The Future
While much progress has been made on this project, I plan to make many changes, updates, and reworks soon:
Make it a GPT
Although the XGBoost architecture worked well enough with the data we had, I would like to explore using a transformer architecture to better capture the context this momentum based data provides. While I was able to capture the rolling averages, this data is much more inflexible compared to the tokenization and attention layers transformers provide. Although not quite a GPT per se, I think repurposing the architecture for the world of sports, which is sequential by nature, may provide even better accuracy and a greater model understanding of the data.
Robust UI
Currently I have a demo of the model functionality which provides predictions and observed data from past games. In the future I plan for this project to become a fun tool for NBA fans to be able to use on any day, look at predicted player and game statistics for the day’s games and compare it to the actual game results. Potentially, as the model becomes more accurate, it may be used as a tool to inform betting patterns. Such an interface would require much more infrastructure and design, which I hope to soon develop.
Better Data Extraction
Right now I am using nba_api to collect data, a free service. There are issues that come with this setup. There is a limit to how much data I can request from an endpoint and how fast I can request the data, so connection losses and timeouts are a major issue that come with collecting data. Additionally there is relatively little documentation on how to use different pieces of data, especially when it comes to a machine learning context like mine. I plan to switch to an alternate location to collect data from for this project.